About the Project
The Super-MuSR spectrometer leverages a 1D convolutional neural network embedded in FPGA to resolve event pile-up in real time, outperforming classical deconvolution and enabling robust hit identification at gigacount rates.
-
Date
May 2025
Nuclear Instruments
STFC - Rutherford Appleton Laboratory
Introduction: Pile-Up, a Bottleneck for Muon Detectors
In high-rate particle physics experiments—such as muon spectroscopy—detectors often face pulse pile-up, where events occur so rapidly that their signals overlap into complex waveforms. To resolve individual pulses within these composite signals, pulse deconvolution techniques are applied. Traditionally executed in software, this process is now increasingly integrated directly into the FPGA of the digitizer. Performing deconvolution on FPGA enables real-time separation of overlapping events, improving the detector’s effective count rate, reducing dead time, and preserving the fidelity of temporal and spectral information.
This need for advanced pulse discrimination has driven the development of a novel, neural network-based approach within the Super-MuSR project at ISIS. By embedding a deep learning model into the acquisition chain, the system enhances pile-up resilience beyond the capabilities of classical deconvolution filters.
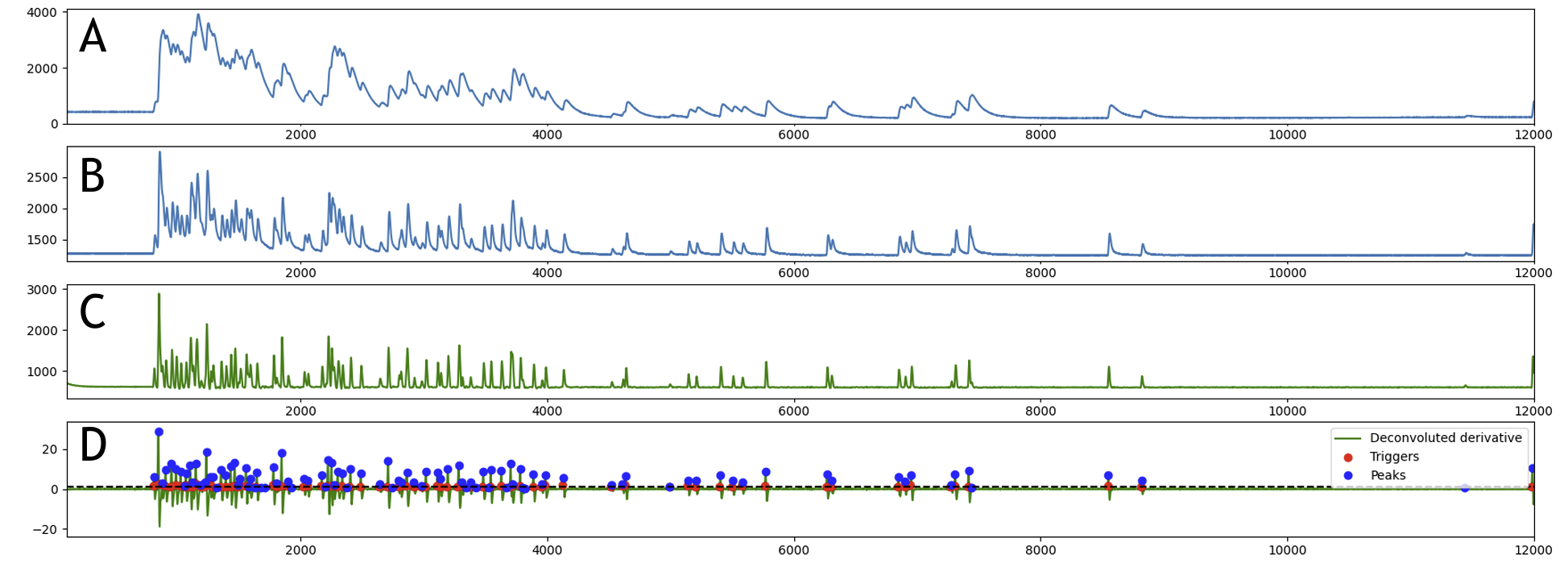
(a) signal from SiPM from a detector placed in the middle of the beam of MUSR. This is the maximum rate we can expect even from future experiments (b) Signal after analog pole-zero implemented on the stave front end. (c) signal after digital deconvolution (d) second derivative of the deconvolved signal used to identify the events (trigger) and the position of the peak.
(a) signal from SiPM from a detector placed in the middle of the beam of MUSR. This is the maximum rate we can expect even from future experiments (b) Signal after analog pole-zero implemented on the stave front end. (c) signal after digital deconvolution (d) second derivative of the deconvolved signal used to identify the events (trigger) and the position of the peak.
Our Contribution: Signal Modeling, AI Inference and FPGA Deployment
Nuclear Instruments played a central role in the Super-MuSR neural pile-up resolution system, focusing on algorithmic development, dataset generation, and FPGA integration. Our contributions include:
- Modeling and simulation of SiPM waveforms with realistic noise, baseline fluctuations, pile-up, and dark counts
- Dataset acquisition directly at the Super-MuSR beamline, capturing high-rate waveforms under real experimental conditions
- Neural network development in Python, including training of the 1D CNN using PyTorch and optimization with Focal Loss for imbalanced classification
- Benchmarking and real-time testing on Jetson Orin Nano, validating inference latency and channel scalability
- FPGA implementation with hls4ml, targeting a Xilinx Zynq UltraScale+ device for embedded inference with sub-frame latency and minimal resource usage
CNN-Based Event Discrimination
A 1D Convolutional Neural Network (CNN) was trained to recognize event pulses within digitized SiPM waveforms sampled at 1 GSps. The network processes raw ADC traces and outputs a binary classification array marking the presence of peaks. Key training strategies included:
- Focal Loss to handle severe class imbalance (few events amid long baselines)
- A realistic simulation set built from millions of test-beam waveforms, accounting for noise, dark counts, and signal variations
- Emphasis on resolving overlapping and low-amplitude events
The resulting model achieved >99.5% accuracy in offline tests, outperforming traditional deconvolution techniques in both accuracy and robustness.
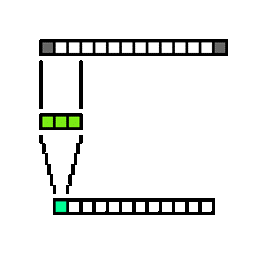
1D Convolution operation applied to the data
1D Convolution operation applied to the data
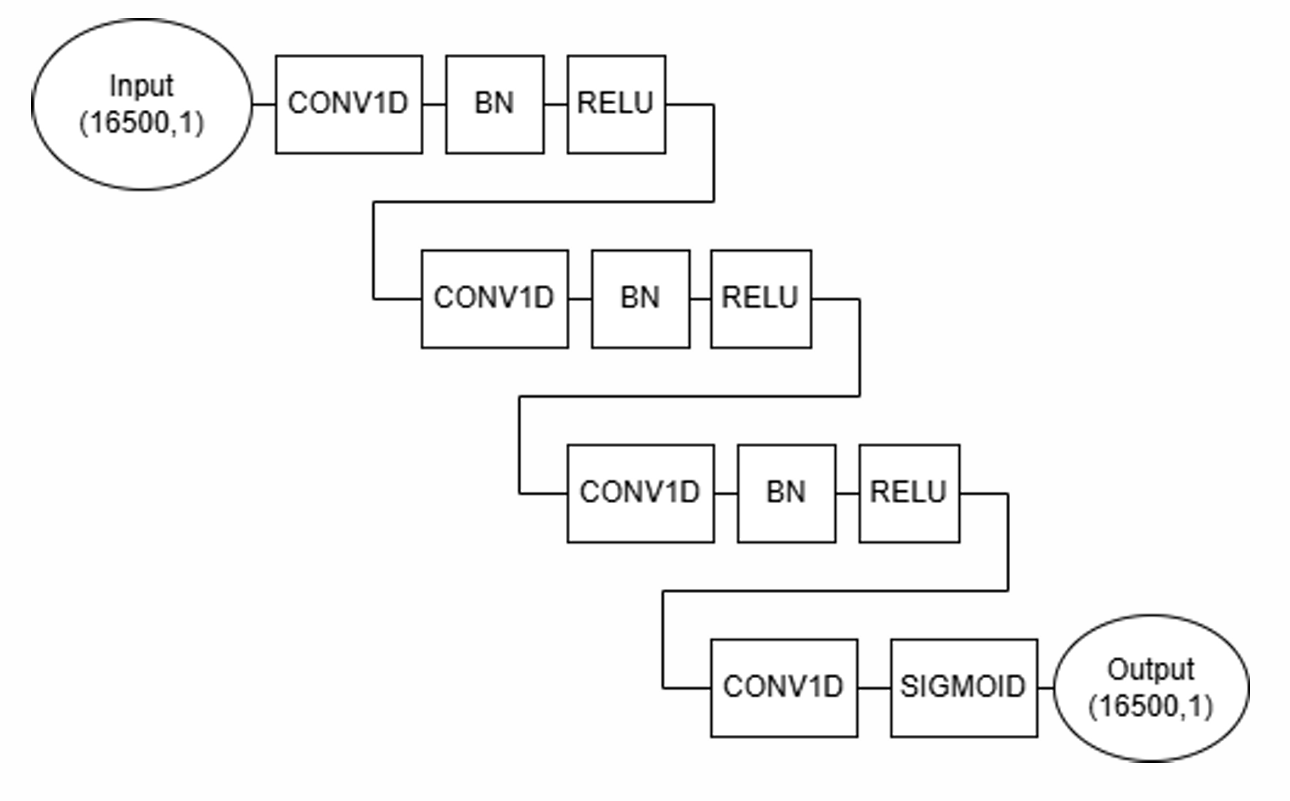
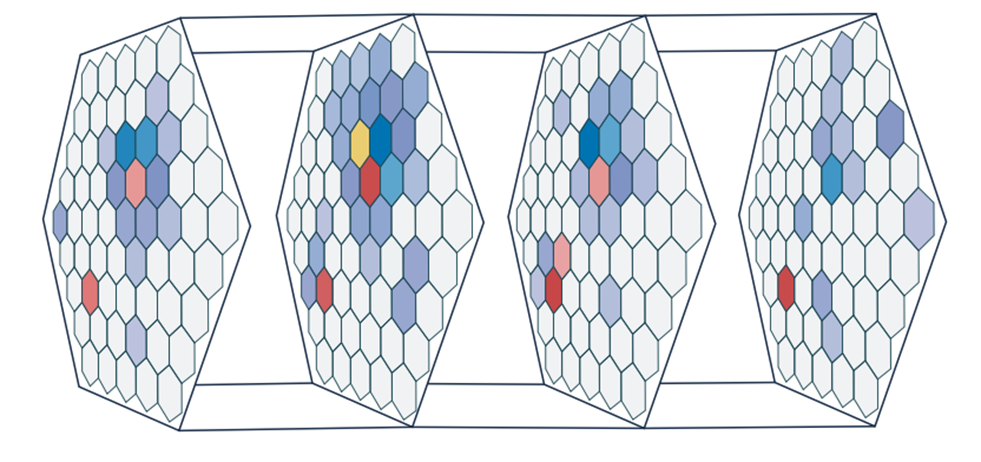
Diagram of the implementation of the CNN-1D neural network used to identify piled-up events
Diagram of the implementation of the CNN-1D neural network used to identify piled-up events
Hardware Deployment: From GPU to FPGA
To support near-detector inference, the trained CNN was deployed in two hardware environments:
1. Jetson Orin Nano
- Implemented using PyTorch
- Processes up to 2 channels in real time at ~40 Hz
- Power dissipation: ~5 W
- Scalable to 16 channels on Jetson AGX Orin, but at the cost of added system complexity
2. Embedded FPGA (hls4ml)
- Targeted a Xilinx Zynq UltraScale+ ZU7EV
- Input waveform split into 128-sample overlapping windows
- Inference latency per sub-frame: ~37 µs
- Resource usage: <10% of available FPGA logic
- Supports 8 parallel channels per board, consuming <200 mW/channel
This on-board inference model eliminates latency and enables a fully autonomous detection system, capable of discriminating events under extreme rate conditions without disrupting the data flow.

Jetson Orin Nano board used for the first tests of the CNN-1D neural network
Jetson Orin Nano board used for the first tests of the CNN-1D neural network

Nuclear Instruments 1 GSPS 32 channel digitizer able to execute the inference in realtime on the data acquired by the SuperMUSR experiment using HLS4ML
Nuclear Instruments 1 GSPS 32 channel digitizer able to execute the inference in realtime on the data acquired by the SuperMUSR experiment using HLS4ML
Impact and Future Outlook
This project demonstrates the first deployment of deep learning pile-up discrimination directly within a high-speed DAQ system for particle detectors. The system is now a key component of Super-MuSR’s readout chain, enabling unprecedented time resolution and event integrity at gigacount scale.
Beyond muon spectroscopy, this approach has wide applicability in:
- Gamma-ray timing detectors
- Neutrino experiments
- Space-based event trackers
- Medical PET systems, where overlapping pulses are common
By embedding intelligence at the edge, detectors can become more selective, efficient, and self-contained—setting the foundation for the next generation of smart instrumentation.
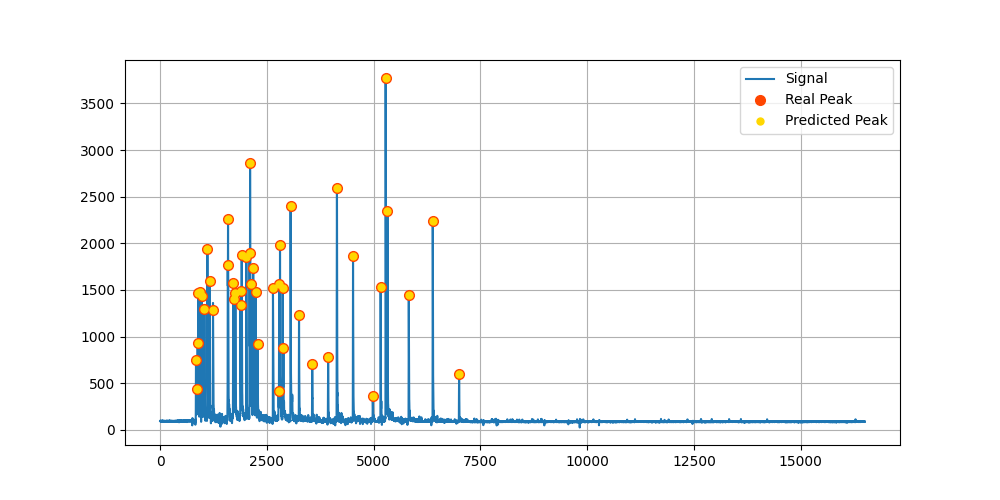
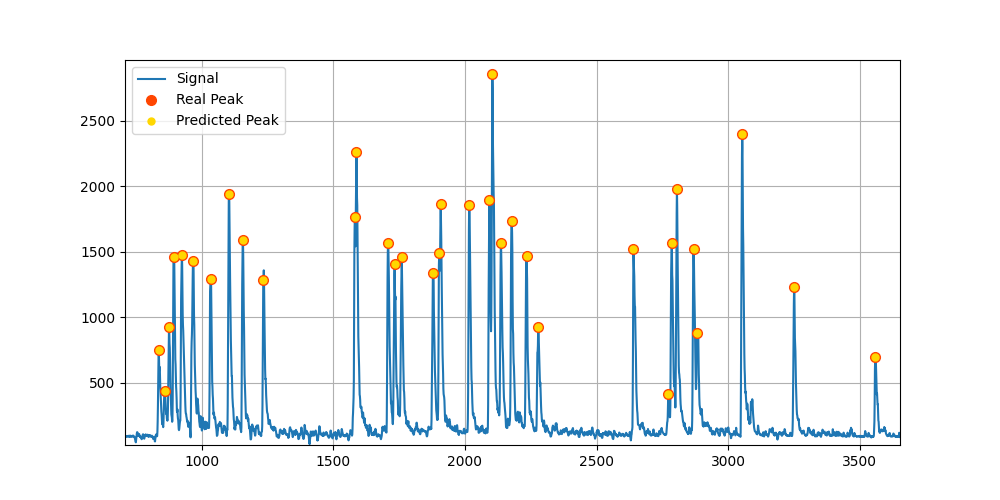
Inference opplied in realtime on a signal acquired on SuperMUSR
Inference opplied in realtime on a signal acquired on SuperMUSR